
I'm joining the Android XR org at Google as a research engineer. I'll be working on synthetic human data for on-device sensing and supporting generative AI applications.
I'm joining the Android XR org at Google as a research engineer. I'll be working on synthetic human data for on-device sensing and supporting generative AI applications.

We present the first method to predict 3D Gaussian reconstructions in real time from a single 2D webcam feed, where the 3D representation is not only live and realistic, but also authentic to the input video. By conditioning the 3D representation on each video frame independently, our reconstruction faithfully recreates the input video from the captured viewpoint (a property we call authenticity), while generalizing realistically to novel viewpoints.

The state of the art in human-centric computer vision achieves high accuracy and robustness across a diverse range of tasks. The most effective models in this domain have billions of parameters. In this paper, we demonstrate that it is possible to train models on much smaller but high-fidelity synthetic datasets, with no loss in accuracy and higher efficiency. Using synthetic training data provides us with excellent levels of detail and perfect labels, while providing strong guarantees for data provenance, usage rights, and user consent.

We propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360-degree rendering.

We introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion.

We present a method for prediction of a person's hairstyle from a single image. e introduce a novel hairstyle taxonomy developed in collaboration with a diverse group of domain experts which we use to balance our training data, supervise our model, and directly measure fairness. We employ an architecture based on a pre-trained feature extraction network in order to improve generalization of our method to real data and predict taxonomy attributes as an auxiliary task to improve accuracy.
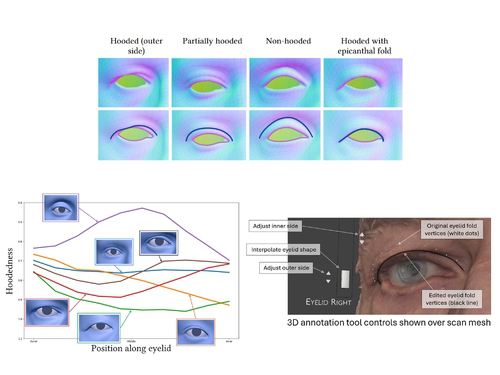
Eyelid shape is integral to identity and likeness in human facial modeling. Human eyelids are diverse in appearance with varied skin fold and epicanthal fold morphology between individuals.
Existing parametric face models express eyelid shape variation to an extent, but do not preserve sufficient likeness across a diverse range of individuals. We propose a new definition of eyelid fold consistency and implement geometric processing techniques to model diverse eyelid shapes in a unified topology.

"Scribble" automatically generates animated 2D avatars from a selfie, stylized based on inclusive art direction. While many face stylizations are biased or inherently limit diversity, we semantically stylize specific facial features to ensure representation. Our diversity-first art direction and stylization approach enables highly stylized yet recognizable 2D avatars.

Our work addresses the problem of egocentric human pose estimation from downwards-facing cameras on head-mounted devices (HMD). This presents a challenging scenario, as parts of the body often fall outside of the image or are occluded. We introduce the SynthEgo dataset, a synthetic dataset with 60K stereo images containing high diversity of pose, shape, clothing and skin tone.

In this report we describe how we construct a parametric model of the face and body, including articulated hands; our rendering pipeline to generate realistic images of humans based on this body model; an approach for training DNNs to regress a dense set of landmarks covering the entire body; and a method for fitting our body model to dense landmarks predicted from multiple views.

State-of-the-art face recognition models show impressive accuracy, but these models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain labeling noise. Most importantly, these face images are collected without explicit consent, raising more pressing privacy and ethical concerns.
To avoid the problems associated with real face datasets, we introduce a large-scale synthetic dataset for face recognition, obtained by photo-realistic rendering of diverse and high-quality digital faces using a computer graphics pipeline.

We boost the realism of our synthetic faces by introducing dynamic skin wrinkles in response to facial expressions and observe significant performance improvements in downstream computer vision tasks. Previous approaches for producing such wrinkles either required prohibitive artist effort to scale across identities and expressions or were not capable of reconstructing high-frequency skin details with sufficient fidelity. Our key contribution is an approach that produces realistic wrinkles across a large and diverse population of digital humans.

We present the first method that accurately predicts ten times as many landmarks as usual, covering the whole head, including the eyes and teeth. This is accomplished using synthetic training data, which guarantees perfect landmark annotations. By fitting a morphable model to these dense landmarks, we achieve state-of-the-art results for monocular 3D face reconstruction in the wild.

We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone.
The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets.

OpticSim.jl is a Julia package for simulation and optimization of complex optical systems developed by the Microsoft Research Interactive Media Group and the Microsoft HART group.
I spent most of 2020 working with Brian Guenter on the package and it has now been open sourced on GitHub.

I'm joining Microsoft's Mixed Reality & AI Labs in Cambridge as a research scientist.
I interned with the group over the summer of 2019 and will be returning permanently to work at the intersection of computer graphics, computer vision and machine learning.

Technical report describing the synthetic faces system which I worked on while with Microsoft over the summer of 2019.

I'm rejoining Microsoft's research lab in Cambridge at the start of 2020 as a research consultant for six eighteen months. I'll be working with the Interactive Media Group on future display technologies.

I'm heading to Tokyo for a three month internship with the R&D department at OLM Digital, starting in September 2019. I'll be building in-house tooling for their 3D animation and visual effects pipelines, primarily developing custom modelling tools for Autodesk Maya.

I'm joining the Cognition research and development team based at Microsoft's lab in Cambridge as a research consultant over the summer of 2019, working on application of machine learning to problems in computer graphics and vision.

Paper introducing the Autonomous Vehicle Acceptance Model (AVAM), a model of user acceptance for autonomous vehicles, adapted from existing models of user acceptance for generic technologies.
Presented at Intelligent User Interfaces 2019.
The complete data and analysis code can be downloaded here
.
I'm taking up a research assistant position at the Computational Media Innovation Centre (CMIC) at the Victoria University of Wellington in New Zealand for three months starting in January 2019.
I'll be working with researchers and industry partners to help develop innovative augmented, virtual and mixed reality technologies.


For my fourth year (masters) project I looked at head pose estimation and facial landmark detection for animals, specifically sheep. This included the adaption of deep learning models for sheep head pose estimation and combination with classical techniques to enable accurate facial alignment. This culminated in the implementation of a near real-time pipeline for farm survellience videos, the end-goal being automated livestock health monitoring.
A condensed version of the dissertation was presented at ACII 2019.

Paper presenting a novel feature set for shape-only leaf identification from images. Over 90% accuracy is achieved on all but one public dataset, with top-four accuracy for these datasets over 98%.
Source code available on GitHub.

Paper focussing on the design, deployment and evaluation of Convolutional Neural Network (CNN) architectures for facial affect analysis on mobile devices. The proposed architectures equal the dataset baseline while minimising storage requirements. A user study demonstrates the feasibility of deploying the models for real-world applications.
Source code is available on GitHub.

Paper presenting a hybrid classification technique using Gaussian processes fitted on features extracted by a convolutional neural network to enable estimation of prediction confidence. The classifier is evaluated on the MNIST dataset and shown to have somewhat meaningful implications for confidence estimation.

I'll be joining the team at Cydar in Cambridge for a two month internship over the summer of 2017.
I will help to develop technologies for medical imaging to be used by surgeons during operations.

For my third year project I explored the procedural modelling of trees for use in computer graphics.
I implemented two systems which generate tree models of many types within the Blender modelling application, one of which now forms the basis of a fully featured plugin.
Source code available on GitHub.

I'm joining the team at Jagex Games Studio for three months in the summer of 2016 as an intern.
I'll be working on a project as part of a small team aimed at exploring new areas which Jagex may be interested in expanding into in the future.


Seng is a sleek and highly customisable replacement for your iOS 8 & 9 app switcher and control center, providing 2 core features; Multi Centre and Hot Corners.
Available to purchase from the Cydia Store.

Customise the iOS LockScreen Now Playing view and Music app. Packed full of features and compatible with all devices running iOS 7 through 9.
Available to purchase from the Cydia Store.

The most fully featured tweak available for modifying the iOS Messages app. Messages Customiser is the one stop solution for tweaking your texting experience on all devices running iOS 7 - 9
Free and Premium version available from the Cydia Store.
Simple winterboard theme with subtle changes from the default iOS 7 look. Inspired by the work of Louie Mantia
Includes all stock icons, and a few extra. Compatible with all devices on iOS 7.
Available from my personal repo.

Chroma, and the more fully featured Tinct, are a duo of UI tweaks for iOS 7 and 8. Both allow for extensive customisation of the colours of various elements of the iOS interface, while remaining lightweight and simple to use.
Chroma is available for free from Cydia (source on GitHub), and Tinct is available to purchase from the Cydia Store.